State capture and feedback#
Many policy pipelines carry information across calls: recurrent hidden state, history windows, previous actions, running statistics, counters, or memory buffers. LEAPP can export that state as part of the graph instead of forcing it to disappear into Python-side control flow.
State capture has two complementary paths:
Explicit state with
state_tensors()andupdate_state(), when you want to name feedback state directly at the call site.Automatic module buffer tracking with
module(), when state already lives inside explicit PyTorch buffers registered on annn.Module.
LEAPP can also infer feedback connections when outputs from later nodes are fed back into earlier nodes across repeated graph execution.
Explicit state capture#
Use state_tensors() for state that should enter a node as
an input and update_state() for the value that should be
fed back on the next call.
State tensors behave like named inputs and outputs: they have explicit tensor
names, shapes, dtypes, and graph ports. The difference is how LEAPP wires them.
A state value declared with state_tensors() connects to the matching value
passed to update_state(), and that connection is exported as feedback for
the next invocation rather than as ordinary forward data flow.
import torch
import leapp
from leapp import annotate
leapp.start("stateful_policy")
obs = annotate.input_tensors("policy", {"obs": torch.randn(1, 16)})
hidden = annotate.state_tensors("policy", {"hidden": torch.zeros(1, 32)})
next_hidden = torch.tanh(torch.cat([obs, hidden], dim=-1))[..., :32]
action = torch.tanh(next_hidden)
annotate.update_state("policy", {"hidden": next_hidden})
annotate.output_tensors("policy", {"action": action}, export_with="jit")
leapp.stop()
leapp.compile_graph(validate=True)
Only states passed to update_state() become feedback state. A state declared
with state_tensors() but never updated remains a regular node input. State
ports are intended for feedback wiring; use input_tensors() and
output_tensors() for normal non-feedback data flow.
Automatic buffer tracking with annotate.module#
For recurrent nn.Module objects, state often already exists as explicit
PyTorch buffers. annotate.module() only tracks tensors that are registered
on an nn.Module with register_buffer(). Register the module with
module(), and LEAPP can track reassigned registered
buffers automatically.
A complete runnable GRU example lives in examples/stateful_gru_export.py.
The model itself stays ordinary PyTorch: it stores hidden state with
register_buffer and reassigns the buffer during forward().
import torch
import torch.nn as nn
import leapp
from leapp import annotate
class GRUPolicy(nn.Module):
def __init__(self, obs_dim=16, hidden_dim=32, action_dim=8):
super().__init__()
self.gru = nn.GRU(obs_dim, hidden_dim, num_layers=1,
batch_first=False)
self.mlp = nn.Sequential(
nn.Linear(hidden_dim, 32),
nn.ELU(),
nn.Linear(32, action_dim),
)
self.register_buffer("h_state", torch.zeros(1, 1, hidden_dim))
def forward(self, obs):
gru_out, h_out = self.gru(obs.unsqueeze(0), self.h_state)
self.h_state = h_out # reassignment detected by LEAPP
return self.mlp(gru_out.squeeze(0))
model = GRUPolicy().eval()
obs = torch.randn(1, 16)
leapp.start("stateful_gru")
obs_traced = annotate.input_tensors("policy", {"obs": obs})
annotate.module("policy", model)
action = model(obs_traced)
annotate.output_tensors(
"policy",
{"action": action},
export_with="onnx-torchscript",
)
leapp.stop()
leapp.compile_graph(visualize=False)
In this example, LEAPP detects that h_state was reassigned during the
forward pass. The exported node receives hidden state as feedback input and
emits the updated hidden state as feedback output.
Note
For recurrent models such as nn.GRU or nn.LSTM, prefer
export_with="onnx-torchscript" when exporting to ONNX.
Buffer tracking details#
annotate.module() temporarily injects traceable versions of selected
registered module buffers while the node executes. When output_tensors()
compiles the node, LEAPP determines which registered buffers changed.
Reassigned buffers become feedback state.
Buffers that are read but not changed are preserved as constants in the exported model.
buffer_names=[...]can restrict tracking to a subset of registered buffers.Plain attributes such as
self.hidden = torch.zeros(...)are not tracked; state must be an explicit registered buffer forannotate.module()to capture it.
Warning
Buffer tracking detects reassignment, such as self.h_state = h_out. It
does not treat in-place mutation such as self.h_state.copy_(h_out) as a
state update. Use reassignment for recurrent state you want LEAPP to export
as feedback.
Automatic feedback detection#
LEAPP also detects graph-level feedback when a later node produces a tensor that is consumed by an earlier node on a later iteration. This is useful when state is managed across multiple logical nodes rather than by one explicit state API.
Annotate the relevant data as normal inputs and outputs with
input_tensors() and output_tensors(). When LEAPP sees tensors produced
by later nodes being used by earlier nodes on a later pass, it automatically
records those connections as feedback.
For inferred cross-node feedback, run the graph at least twice inside the same
leapp.start() / leapp.stop() session so LEAPP can observe the re-entry.
A complete runnable version of this pattern lives in
examples/feedback_example.py:
import torch
import leapp
from leapp import annotate
def mix_with_feedback(data, feedback):
centered = data - 0.5
return torch.tanh(centered + 0.25 * feedback)
def blend_feedback(hidden, previous_feedback):
return 0.8 * previous_feedback + 0.2 * hidden
leapp.start(name="sample_feedback_graph")
policy_memory = torch.tensor([0.0])
for _ in range(2): # needed for inferred cross-node feedback
policy_inputs = annotate.input_tensors("policy_step", {
"observation_scalar": torch.tensor([1.0]),
"policy_memory_in": policy_memory,
})
policy_context = mix_with_feedback(policy_inputs[0], policy_inputs[1])
control_action = torch.clamp(policy_context * 2.0, min=-1.0, max=1.0)
annotate.output_tensors(
"policy_step",
{"policy_context": policy_context,
"control_action": control_action},
export_with="jit",
)
feedback_inputs = annotate.input_tensors("feedback_update", {
"policy_context": policy_context,
"policy_memory_prev": policy_memory,
})
policy_memory = blend_feedback(feedback_inputs[0], feedback_inputs[1])
annotate.output_tensors(
"feedback_update",
{"policy_memory_out": policy_memory},
export_with="jit",
)
leapp.stop()
leapp.compile_graph()
In this example, policy_memory_out flows from feedback_update back into
policy_step/policy_memory_in on the next iteration, creating a feedback
connection.
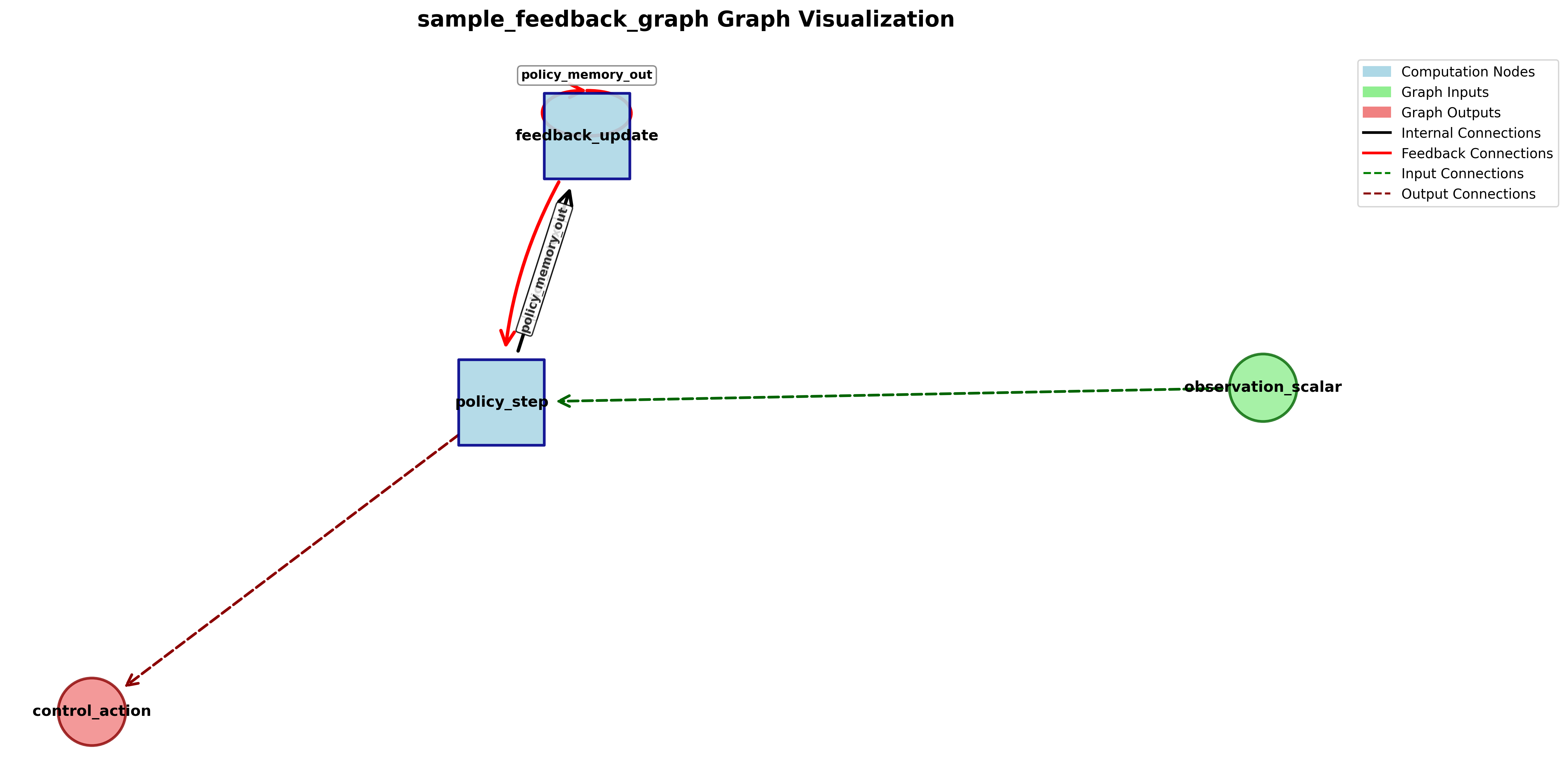
Detected feedback is serialized under feedback_flow in the generated YAML:
feedback_flow:
feedback_update/policy_memory_out:
- policy_step/policy_memory_in
- feedback_update/policy_memory_prev
Important considerations#
Warning
Minimum two iterations required for inferred feedback. The first iteration traces nodes and establishes direct connections. The second iteration lets LEAPP observe data flowing back to earlier nodes.
Explicit state declared with state_tensors() / update_state() or
detected via annotate.module() can produce feedback metadata in one
trace.
Note
Port names are preserved. LEAPP emits source and target port names as
annotated. Downstream frameworks should read the explicit data_flow /
feedback_flow mappings rather than assuming connected port names match.
Summary#
Use
state_tensors()andupdate_state()for explicit recurrent state.Use
annotate.module()to capture reassignednn.Modulebuffers such as GRU or LSTM hidden state.Run repeated graph iterations when you want LEAPP to infer cross-node feedback automatically.